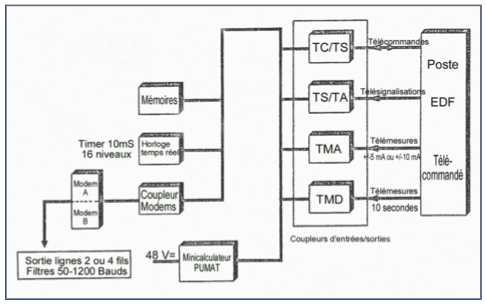
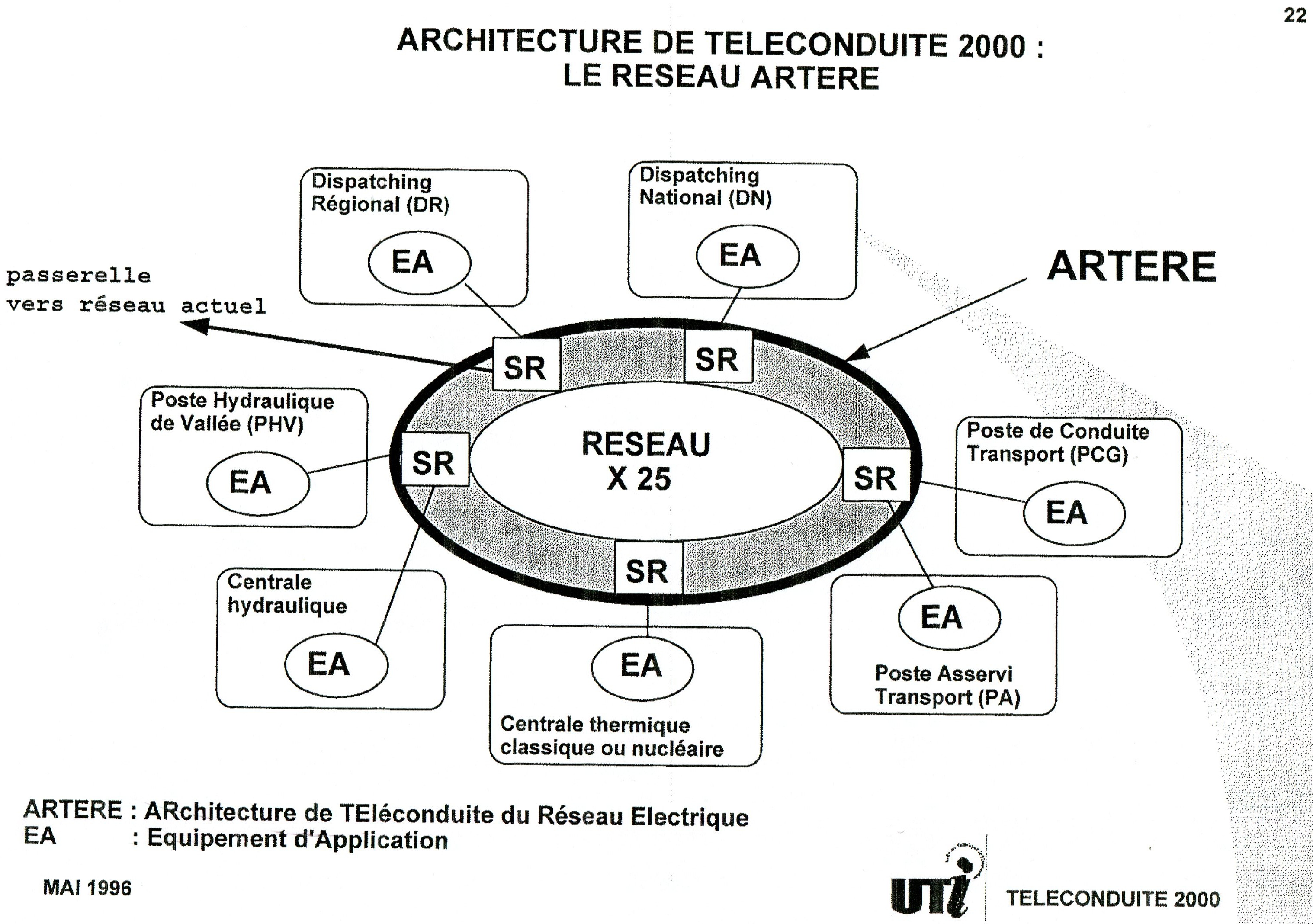
Le développement du logiciel sur C 90-40
Le développement initial
Nous n’avons pas retrouvé suffisamment d’informations sur les développements initiaux pour compléter les informations de l’article principal, aussi nous focaliserons nous sur les développements complémentaires qui ont émaillé toute la longue vie des C 90-40.
Il est à noter qu’en dehors du développement de modèles de calcul de réseau effectué par la Direction des Etudes et Recherches, les autres développements ont été effectués par les équipes régionales avec très ponctuellement un soutien externe de CII.
Les développements ultérieurs
Le besoin
Les besoins étaient issus des exploitants du système électrique ou de la partie informatique. Dans les deux cas le besoin pouvait présenter un caractère local, mutuel ou national. Dans tous les cas, une information mutuelle et réciproque était mise en place et permettait le partage des bonnes pratiques et des bonnes idées.
L’analyse
Une fois le besoin globalement exprimé, venait une phase d’analyse qui au-delà de la simple analyse du logiciel concerné, comportait un volet important sur l’impact sur les ressources mémoire vive (place, cartographie mémoire), ressources disque (place, cartographie disque), sur les ressources CPU. Compte tenu de l’optimisation poussée des ressources, l’ajout d’un simple marqueur tenant sur un bit, pouvait amener à des chamboulements des implantations, voire à une reprise globale de la cartographie disque ou mémoire, ce qui était toujours une opération très risquée, car elle impactait tous les sources des programmes, mais aussi éventuellement les performances en jouant sur les temps d’accès au disque.
Pour les programmes au cœur du système comme le scheduler, l’optimisation allait jusqu’à comparer le nombre global de temps de cycles machine de séquences réalisant le même objectif, mais avec des codages différents.
Le codage
Quasiment toutes les tâches tournant en temps réel étaient écrites en assembleur. Les autres, de moindre récurrence, étaient écrites en Fortran II temps réel, qui permettait d’inclure des séquences d’instructions assembleur. Il nous souvient que les temps globaux (analyse, codage, tests, intégration) pour la production d’un programme en assembleur étaient de l’ordre de 15% supérieurs à ceux de la production en Fortran. Par contre la maintenance évolutive ultérieure était beaucoup plus laborieuse en assembleur qu’en Fortran.
La production
Saisie
Après écriture sur papier du code, la saisie, que ce soit en assembleur ou en Fortran, se traduisait par la perforation sur cartes, à raison d’une ligne de code par carte, sur un perforateur de cartes disposant d’un clavier de type machine à écrire, et sans aucun écran.. La perforation se faisant en direct, toute faute de frappe signifiait une nouvelle frappe complète de la carte, ce qui amenait à être méticuleux dans la préparation et la frappe.
A chaque programme ou sous programme correspondait un paquet de cartes qui était la référence de base pour les modifications ultérieures et qu’il fallait donc conserver dans son intégrité. (Quelques anecdotes sur le développement du logiciel )
Assemblage ou compilation
Une fois la saisie terminée, les cartes étaient placées dans le lecteur perforateur et une commande depuis la console système (une télétype de type KSR, petite merveille de mécanique et de tringlerie puis de type ASR) lançait la lecture des cartes puis l’assemblage ou la compilation. Il en sortait un ruban binaire dont l’adresse d’implantation pouvait être fixe ou translatable. Si le programme comportait des sous-programmes, l’opération devait être répétée à l’identique pour chacun d’eux.
Pour un logiciel écrit en FORTRAN, le mode opératoire était légèrement différent de celui utilisé pour l’assembleur. Comme le compilateur FORTRAN ne tenait pas en mémoire, le dérouleur de bande était utilisé comme mémoire auxiliaire et la compilation s’effectuait en plusieurs passes.
Comme dans les temps actuels, assembleur et compilateur détectaient les erreurs de syntaxe, mais de façon beaucoup moins performante.
Edition de liens
Une autre commande lançait l’édition de liens ; il fallait alors lire les différents rubans obtenus dans l’étape précédente ainsi que la table des symboles qui permettait de faire le lien entre les références externes du programme (routines système, adresses physiques des données résidentes en mémoire, adresses des fichiers, etc). L’édition de lien se terminait par la production de l’exécutable sur un ruban perforé à partir d’un lecteur perforateur de ruban. Une fois la perforation terminée, le rouleau obtenu qui pouvait atteindre une taille importante, devait être remonté sur le lecteur perforateur. Une dernière commande lançait la lecture du ruban perforé et l’installation de l’exécutable sur disque. La lecture du ruban perforé s’accompagnait d’un contrôle de parité. Il suffisait alors d’une seule erreur de perforation pour que l’opération échoue. Dans ce cas, le ruban partait à la poubelle et il fallait recommencer.
La mise au point
La mise au point était laborieuse en l’absence d’outils de débogage et de plateforme de tests.
La procédure consistait à d’abord à lancer le programme dans un environnement figé sur le calculateur scientifique, puis une fois les limites de cette méthode atteinte, de passer, après avoir obtenu l’accord du dispatching, sur la machine fonctionnant en temps réel tout en gardant celle utilisée en secours avec la version ancienne, au cas où…
En cas de problème, dans les deux cas cités ci-dessus, le mode opératoire consistait tout d’abord à ajouter des traces (impression papier ou écriture dans un espace mémoire dédié à cet effet). L’ajout de traces pouvant modifier le fonctionnement du programme (décaler un écrasement en mémoire par exemple et le rendre non détectable), la deuxième méthode consistait à insérer dans le programme des instructions « HLT » (halte). Le calculateur s’arrêtait. On pouvait alors, en actionnant une clé, faire fonctionner le calculateur en pas à pas et consulter au pupitre les registres de calcul matérialisés par 24 lampes (parmi les registres on pouvait visualiser selon la position d’une molette, le registre C contenant l’instruction en cours de décodage, les registres A (accumulateur principal), B (extension de l’accumulateur), X (registre d’index), P (compteur qui indiquait l’emplacement mémoire de l’instruction en cours)).
A l’aide de l’accessibilité à ces registres on pouvait visualiser des zones mémoire, faire des patches en mémoire (en savoir plus). Cette méthode amenait les ingénieurs qui maîtrisaient cette technique à connaître par cœur les codes (en octal ) des instructions les plus courantes et à savoir effectuer avec une certaine dextérité les opérations courantes en base huit pour recalculer les emplacements mémoire visés.
Pendant tout ce temps les dispatcheurs devaient se contenter du synoptique, des enregistreurs et du téléphone….
Maigre consolation, les dumps mémoire étaient de taille raisonnable et relativement facile à décrypter en l’absence de structures systèmes complexes.